Credit Risk Prediction
Borrower default-risk classification with imbalance handling and SHAP explainability.
- scikit-learn
- XGBoost
- pandas
- SHAP
- Python
- GitHub available
- SHAP explainability
- ROC + confusion matrix
- Cross-validated
At a glance
- Problem
- Can we estimate a borrower's probability of default and explain what drives the risk?
- Built
- A full classification pipeline with feature engineering, model comparison and SHAP explanations.
- Models / methods
- Logistic regression, random forest and gradient boosting, compared with cross-validation.
- Result
- Best model selected on cross-validated AUC; drivers surfaced with SHAP.
- Strength shown
- Honest model comparison, class-imbalance handling, explainable output.
- Links
- GitHubCase Study
Visual proof
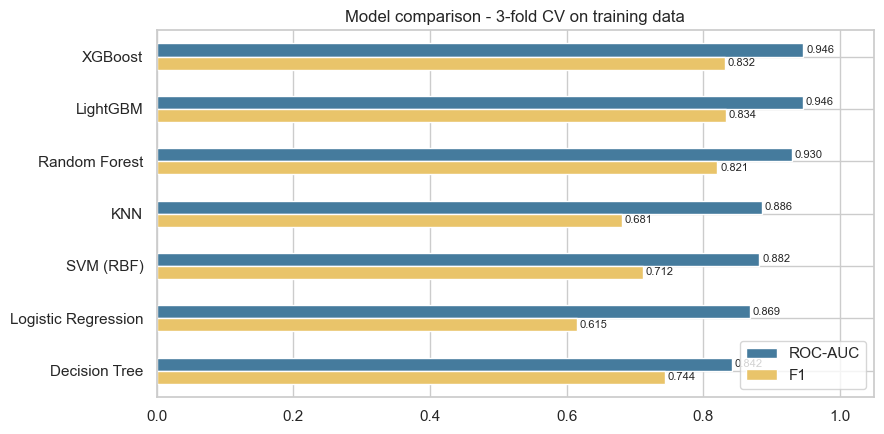
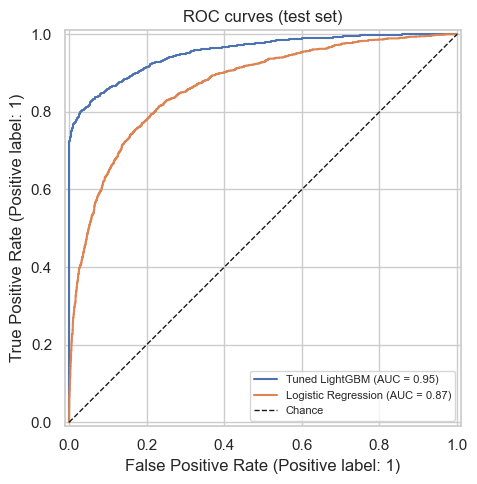
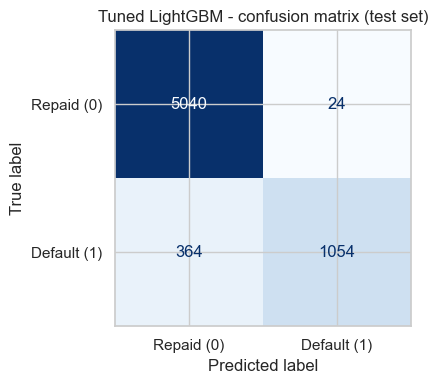
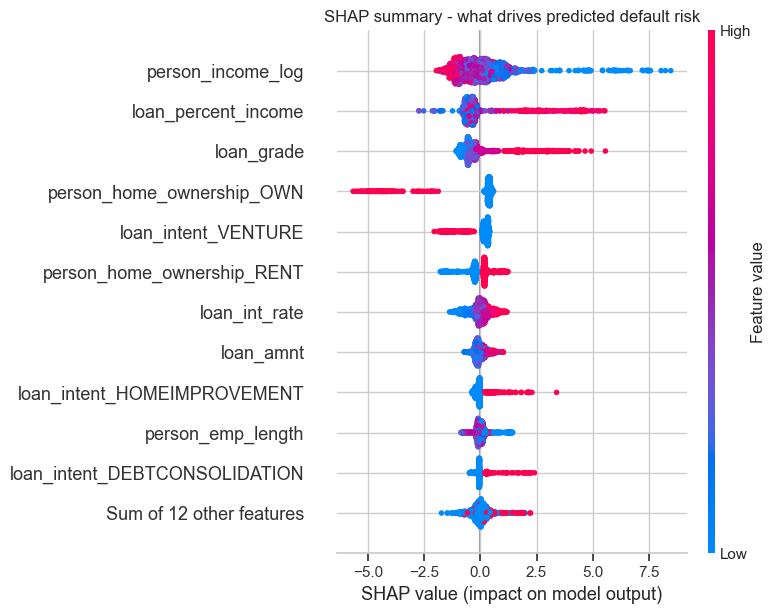
Charts and diagrams are real outputs and architecture from the project.
01Objective
Classify borrowers by default risk and explain the drivers, so decisions are both accurate and defensible.
02Dataset / input
A public credit dataset of applicant and loan attributes, with default as the binary target.
03Model approach
- Feature engineering and encoding on applicant/loan attributes
- Cross-validated comparison of logistic regression, random forest and gradient boosting
- Class-imbalance handling and threshold selection
04Results / metrics
Models compared on 3-fold CV AUC; the chosen model is reported with its ROC curve and confusion matrix. SHAP shows which features push a prediction toward default.
05Deployment / reproducibility
Reproducible notebooks (EDA + modelling) that run end to end.
06Limitations
- Single public dataset; real lending data would shift the distribution
- No fairness/bias audit in this version
07Future improvements
- Probability calibration tied to lending policy
- A fairness and bias review
08Key takeaway
A complete, explainable risk classifier — compared honestly and interrogated with SHAP, not just a single accuracy number.