NLP Retrieval & RAG
An information-retrieval and retrieval-augmented question-answering system on Natural Questions.
- Python
- FAISS
- Transformers
- Flan-T5
- NLP
- GitHub available
- Retrieval demo
- Re-ranking
- Reproducible notebook
At a glance
- Problem
- How well can a system answer natural-language questions over a document collection, and what does re-ranking add?
- Built
- TF-IDF, dense and hybrid retrieval baselines with FAISS, cross-encoder re-ranking and Flan-T5 generation.
- Models / methods
- TF-IDF, dense embeddings, a cross-encoder re-ranker, and Flan-T5.
- Result
- The dense + cross-encoder stack improved candidate quality over the TF-IDF baseline; grounding reduced unsupported answers.
- Strength shown
- IR fundamentals, retrieval evaluation, end-to-end RAG.
- Links
- GitHubCase Study
Visual proof


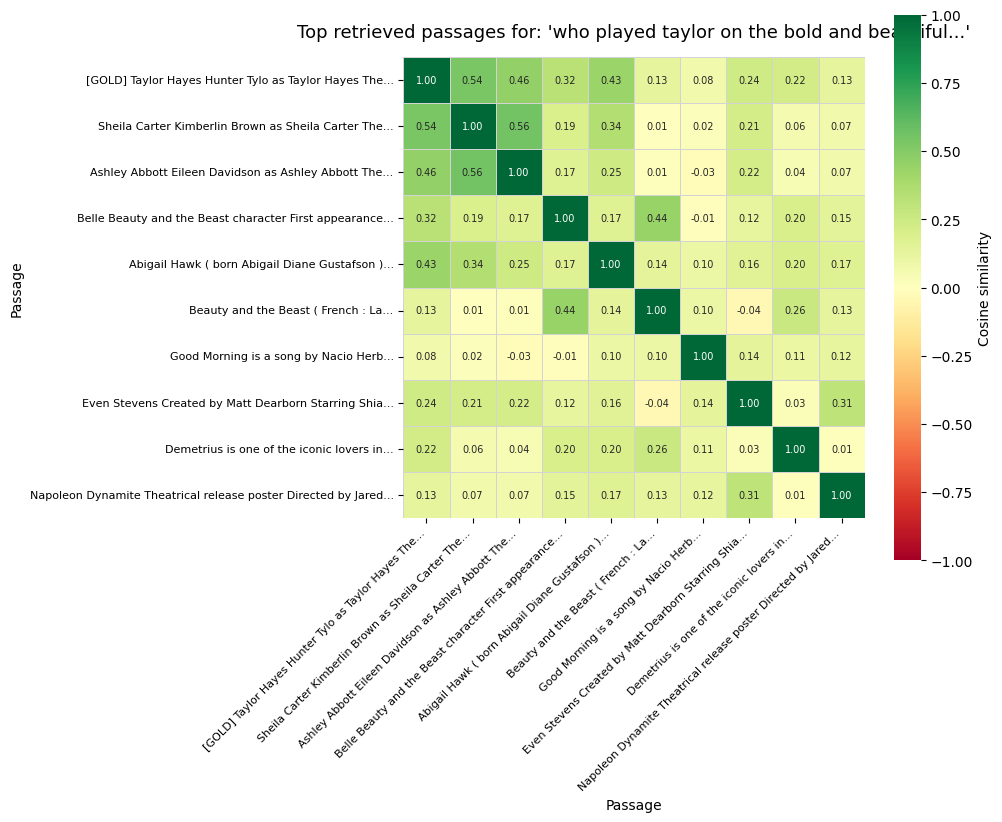
Charts and diagrams are real outputs and architecture from the project.
01Objective
Answer natural-language questions over a document collection, comparing retrieval strategies and measuring how much re-ranking and generation add.
02Dataset / input
The Natural Questions benchmark — real user questions paired with Wikipedia passages — used for both retrieval and answer evaluation.
03Model approach
- TF-IDF, dense, and hybrid retrieval baselines
- FAISS for efficient nearest-neighbour search over embeddings
- A cross-encoder to re-rank the top candidates
- Flan-T5 to generate grounded answers from retrieved context
04Results / metrics
Retrieval compared with standard IR metrics (recall@k, MRR); the dense + cross-encoder stack improved candidate quality over the TF-IDF baseline, and grounding generation in retrieved passages reduced unsupported answers. The similarity heatmap shows the top retrieved passages for a sample query.
05Deployment / reproducibility
Delivered as reproducible notebooks and scripts that run the full pipeline from indexing through evaluation.
06Limitations
- Compute-bound to a subset of the full benchmark
- Generation quality bounded by a small, open generator model
07Future improvements
- Larger instruction-tuned generators and query rewriting
- Answer-faithfulness scoring and citation checking
08Key takeaway
Demonstrates the retrieval fundamentals behind modern RAG — baselines, dense search, re-ranking and grounded generation — measured properly.